

Packet Capture Data Integrity
Sadly most network packet capture systems like to talk about how shiny fast their capture rate is or the huge amount of CPU/RAM/IO/X the system has. But how often do they discuss reliability of stored captured data? after all whats the point of capturing all this data only to have it bit-rot away?

Data loss can occur in many places within a packet capture system, the 1st location is packet drops by the NIC, the 2nd place is packet drops due to lack of disk IO, and the 3rd place is typically catastrophic disk failures. However there is a 4th place that is always overlooked in capture systems and that is bit-rot data decay, or put another way death by silent disk corruption. Silent disk corruption is when the storage media has small bit errors in the write or read operation that go completely undetected. This the most damaging type of failure is? Why ? because its a silent failure.
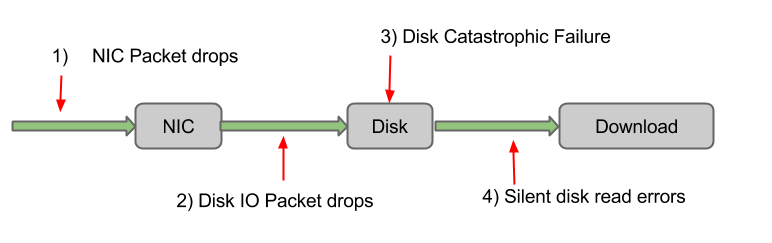
Why silent? because your raid controllers (including sw raid) are not doing parity checks when reading from the disk, to do so severely reduces read bandwidth. They are only performed when scribing the disks and this is usually left uncofigured.
Imagine the following situations.
- 1) Silent disk corruption occurs "data decay/data rot/bit rot"
- 2) A disk suffers a catastrophic failure
- 3) RAID system rebuilds the array
OR
- 1) Silent disk corruption occurs "data decay/data rot/bit rot"
- 2) A capture is downloaded
- 3) Analytics can not process the PCAP
In the catastrophic disk failure situation you might expect RAID5/RAID10/RAID50 would save your ass^H^H^H data? ... it does not. Because you`ve actually lost 2 disks for some part of the data (bitrotted parts + entire drive loss) and RAID5/10/50 can not recover.
Bottom line is, for silent disk read corruption RAID does not help at all.
The folks over at the ZFS club like to proudly state their system does checksums at the file level, and thus ZFS detects and automatically corrects all bit-rot silent read corruption errors. Our fmadio 10G packet capture systems does not use ZFS but we have gloriously stolen the idea.
"the most damaging type of failure is a silent failure"
We checksum like crazy. Everywhere, anywhere, anytime and constantly. Firstly even before the packets hits the disks, a master CRC is calculated when the packets are still in ECC RAM, DMA`ed directly by the NIC. This is the closest we can get to an absolute verification checksum of the (dropless) raw packet data.
The second checksum is calculated from data on the 1TB of flash cache, and the third checksum from data on the RAID5 magnetic disk array. It should be noted there is a unique checksum for every 256KB worth of captured data (its not a single file checksum). And finally when its time for you to process and download a capture. Every 256KB worth of data read from cache or disk has its checksum calculated and verified against our golden master checksum, that was meticulously calculated way back when it was freshly captured into ECC RAM.

But there is more! We have a programable maintenance cycle which sweeps every single byte on the system, checking for bit-rot as well as SMART errors, RAM ECC errors and a range of other integrity checks. Ideally this is scheduled to run every night, assuming the system has some downtime or run at least once a week.
"no surprises"
The philosophy is, when the system is always reading and verifying every single byte of captured data, every day, every week, every month. Small problems are detected early, are detected accurately and corrective action applied before cascading into more difficult problems. This removes the guess work by knowing the precise health of the system, creating stability with no surprises.


